-
ID3 모델 구현_Python(2)_전체모델머신러닝(MACHINE LEARNING)/간단하게 이론(Theory...) 2021. 4. 26. 15:16반응형
0. 전체 코드 구현
-주석을 다 뺐으며, 밑의 코드분석에는 주석을 달아 놓았습니다.
ID3 모델 구현 Tree 의 마지막 단계 글입니다.
https://guru.tistory.com/entry/ID3-%EB%AA%A8%EB%8D%B8-%EA%B5%AC%ED%98%84Python
ID3 모델 구현_Python
저번에 살펴본 ID3 모델을 이제는 Python으로 간략히 구현해보자. 혹시나 ID3모델이 무엇인지 모른다면 , 저번 포스팅을 참고해보자 https://guru.tistory.com/entry/Decision-Tree-%EC%97%90%EC%84%9C%EC%9D%98-I..
guru.tistory.com
import numpy as np import pandas as pd eps = np.finfo(float).eps from numpy import log2 as log outlook = 'overcast,overcast,overcast,overcast,rainy,rainy,rainy,rainy,rainy,sunny,sunny,sunny,sunny,sunny'.split(',') temp = 'hot,cool,mild,hot,mild,cool,cool,mild,mild,hot,hot,mild,cool,mild'.split(',') humidity = 'high,normal,high,normal,high,normal,normal,normal,high,high,high,high,normal,normal'.split(',') windy = 'FALSE,TRUE,TRUE,FALSE,FALSE,FALSE,TRUE,FALSE,TRUE,FALSE,TRUE,FALSE,FALSE,TRUE'.split(',') play = 'yes,yes,yes,yes,yes,yes,no,yes,no,no,no,no,yes,yes'.split(',') dataset = {'outlook': outlook, "temp": temp, "humidity":humidity, "windy":windy, "play":play} df = pd.DataFrame(dataset, columns = ['outlook','temp','humidity','windy','play']) df def find_entropy(df): Class = df.keys()[-1] entropy = 0 values = df[Class].unique() for value in values: fraction = df[Class].value_counts()[value]/len(df[Class]) entropy += -fraction*np.log2(fraction) return entropy def find_entropy_attribute(df,attribute): Class = df.keys()[-1] target_variables = df[Class].unique() variables = df[attribute].unique() entropy2 = 0 for variable in variables: entropy = 0 for target_variable in target_variables: num = len(df[attribute][df[attribute] == variable][df[Class]==target_variable]) den = len(df[attribute][df[attribute] == variable]) fraction = num/(den+eps) entropy+= -fraction*log(fraction) fraction2 = den/len(df) entropy2 += -fraction2*entropy return entropy2 def find_winner(df): Entropy_att = [] IG = [] for key in df.keys()[:-1]: IG.append(find_entropy(df)-find_entropy_attribute(df,key)) return df.keys()[:-1][np.argmax(IG)] def get_subtable(df,node,value): return df[df[node] == value].reset_index(drop=True) def buildTree(df,tree=None): Class = df.keys()[-1] node = find_winner(df) attValue = np.unique(df[node]) #Create an empty dictionary to create tree if tree is None: tree={} tree[node] = {} for value in attValue: subtable = get_subtable(df,node,value) clValue,counts = np.unique(subtable[Class],return_counts=True) if len(counts)==1: tree[node][value] = clValue[0] else: tree[node][value] = buildTree(subtable) return tree1. 데이터 로딩
-앞선 데이터를 그대로 사용하여 pandas 라이브러리에 로딩 시킨다.
In [1]:import numpy as np import pandas as pd # eps 란 numpy에서 가장 작은 수를 의미하는 수이다. eps = np.finfo(float).eps from numpy import log2 as logIn [2]:# data set 을 생성해준다. 날씨 데이터 안에는 outlook(날씨),temp(온도) # humidity(습기),windy(바람),play(경기를 하는지 여부) 에 관한 속성들이 담겨있다. outlook = 'overcast,overcast,overcast,overcast,rainy,rainy,rainy,rainy,rainy,sunny,sunny,sunny,sunny,sunny'.split(',') temp = 'hot,cool,mild,hot,mild,cool,cool,mild,mild,hot,hot,mild,cool,mild'.split(',') humidity = 'high,normal,high,normal,high,normal,normal,normal,high,high,high,high,normal,normal'.split(',') windy = 'FALSE,TRUE,TRUE,FALSE,FALSE,FALSE,TRUE,FALSE,TRUE,FALSE,TRUE,FALSE,FALSE,TRUE'.split(',') play = 'yes,yes,yes,yes,yes,yes,no,yes,no,no,no,no,yes,yes'.split(',') dataset = {'outlook': outlook, "temp": temp, "humidity":humidity, "windy":windy, "play":play} df = pd.DataFrame(dataset, columns = ['outlook','temp','humidity','windy','play'])In [3]:dfOut[3]:outlook temp humidity windy play 0 overcast hot high FALSE yes 1 overcast cool normal TRUE yes 2 overcast mild high TRUE yes 3 overcast hot normal FALSE yes 4 rainy mild high FALSE yes 5 rainy cool normal FALSE yes 6 rainy cool normal TRUE no 7 rainy mild normal FALSE yes 8 rainy mild high TRUE no 9 sunny hot high FALSE no 10 sunny hot high TRUE no 11 sunny mild high FALSE no 12 sunny cool normal FALSE yes 13 sunny mild normal TRUE yes 2. find_entropy(df) 함수
- find_entropy(df) 함수의 구현이다. df["play"] 의 'yes' 와 'No'를 기준으로 나눈 엔트로피값을 계산.
In [4]:def find_entropy(df): #Class 내부에 df.keys()[:-1]로 df["play"]속성값들을 넣어준다. Class = df.keys()[-1] entropy = 0 values = df[Class].unique() #values 를 통해 df[Class] 내부의 entropy 계산 한다. 계산과정은 전과 동일 for value in values: fraction = df[Class].value_counts()[value]/len(df[Class]) entropy += -fraction*np.log2(fraction) return entropy3. find_entrophy_attribute 함수 구현
- finde_entrophy_attribute 함수는 df, attribute를 받아 , df내부의 attribute 속성을 기준으로 나누었을때, df의 entropy 값이 어떻게 바뀌는지를 return 해주는 함수이다.
In [5]:def find_entropy_attribute(df,attribute): Class = df.keys()[-1] target_variables = df[Class].unique() variables = df[attribute].unique() entropy2 = 0 for variable in variables: entropy = 0 #target_variables 즉 "yes", "no"를 기준으로 엔트로피를 계산해준다. for target_variable in target_variables: num = len(df[attribute][df[attribute] == variable][df[Class]==target_variable]) den = len(df[attribute][df[attribute] == variable]) fraction = num/(den+eps) entropy+= -fraction*log(fraction) # fraction2 는 attribute가 df에서 얼마만큼의 비율에 해당하는지를 곱해준다. fraction2 = den/len(df) entropy2 += -fraction2*entropy return entropy24. find_winner 함수 구현
-find_winner 함수는 df 내부에서 attribute 속성값을 기준으로 나뉘었을때, 어떤 attribute가 가장 큰 entropy 감소량이 있는 지 확인 후, attribute 를 return 한다.
In [6]:def find_winner(df): Entropy_att = [] IG = [] for key in df.keys()[:-1]: IG.append(find_entropy(df)-find_entropy_attribute(df,key)) return df.keys()[:-1][np.argmax(IG)]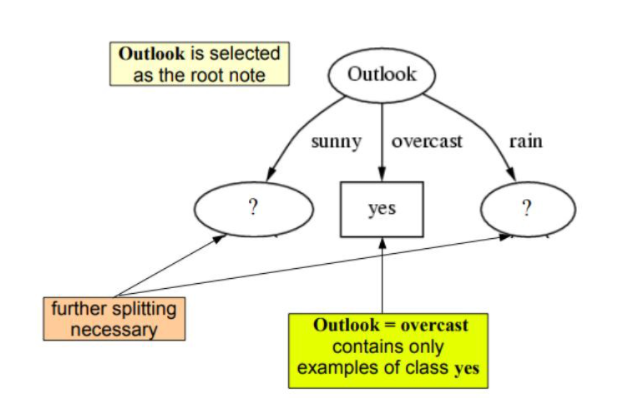
outlook기준으로 나뉘게 되었을때, 트리 모형 5. get_substable 함수 구현
- get_substable 함수는 df의 값중에서 node값(속성값)이 value와 같은 값들을 drop 해준다.
- 즉, get_substable(df,"outlook","sunny") 이면, df[df["outlook"] == "sunny" 인 값들만 따로 빼내어 return 해준다.In [7]:def get_subtable(df,node,value): return df[df[node] == value].reset_index(drop=True)6. Tree 모델 구현
- tree 모델 구현이다. tree 는 따로 클래스를 지정해주지 않고, 그냥 함수로 정의하여, tree 를 구현해주었다.
- tree 가 처음 주어 지지 않았다면 dict 형태를 만들어주고, df[node(attribute,즉 속성값이 들어감) : {내부의 값들}] 의 형태로 tree 를 만들어주게 되었다.
In [8]:def buildTree(df,tree=None): Class = df.keys()[-1] node = find_winner(df) attValue = np.unique(df[node]) # 빈 트리를 생성해준다. if tree is None: tree={} tree[node] = {} for value in attValue: subtable = get_subtable(df,node,value) # subtable을 기준으로 subtable["play"] 값이 "yes" 이거나 "no"밖에 없다면 # counts = 1 이게 되어, tree[node][value] = clValue("yes" 또는 "no")값을 가지게 된다. # "yes","no" 섞여 있다면 counts=2, subtable을 기준으로 다시 나누어준다.. clValue,counts = np.unique(subtable[Class],return_counts=True) if len(counts)==1: tree[node][value] = clValue[0] else: tree[node][value] = buildTree(subtable) return treeIn [9]:t = buildTree(df)<ipython-input-5-45e83dca9d92>:12: RuntimeWarning: divide by zero encountered in log2 entropy+= -fraction*log(fraction) <ipython-input-5-45e83dca9d92>:12: RuntimeWarning: invalid value encountered in double_scalars entropy+= -fraction*log(fraction)7. 최종 df 의 tree 값들
In [10]:
tOut[10]:{'outlook': {'overcast': 'yes', 'rainy': {'windy': {'FALSE': 'yes', 'TRUE': 'no'}}, 'sunny': {'temp': {'cool': 'yes', 'hot': 'no', 'mild': {'humidity': {'high': 'no', 'normal': 'yes'}}}}}}반응형'머신러닝(MACHINE LEARNING) > 간단하게 이론(Theory...)' 카테고리의 다른 글
행사다리꼴 행렬(echelon form matrix)이란 (0) 2021.04.29 가우스 소거법 (Gauss_Elimination) (0) 2021.04.28 ID3 모델 구현_Python (2) 2021.04.26 Decision Tree 에서의 ID3 알고리즘 (0) 2021.04.25 간단한 LinearRegression 으로 Boston_price 예측 (1) 2021.04.22
